Chapter 12
Monte Carlo Radiation Transport
12.1 Transport and Collisions
Consider the passage of uncharged particles through matter. The
particles might be neutrons, or photons such as gamma rays. The matter
might be solid, liquid, or gas, and contain multiple species with
which the particles can interact in different ways. We might be
interested in the penetration of the particles into the matter from
the source, for example what is the particle flux at a certain place,
and we might want to know the extent to which certain types of
interaction with the matter have taken place, for example radiation
damage or ionization. This sort of problem lends itself to modelling
by Monte Carlo methods.
Since the particles are uncharged, they travel in straight lines at
constant speed between collisions with the matter. Actually the
technique can be generalized to treat particles that experience
significant forces so that their tracks are curved. However, charged
particles generally experience many collisions that perturb their
velocity only very slightly. Those small-angle collisions are not so
easily or efficiently treated by Monte Carlo techniques, so we
simplify the treatment by ignoring particle acceleration between
collisions.
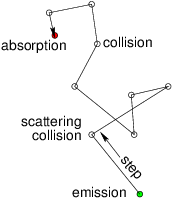
Figure 12.1: A random walk is executed by a particle with
variable-length steps between individual scatterings or
collisions. Eventually it is permanently absorbed. The statistical
distribution of the angle of
scattering is determined by the details of the collision
process.
12.1.1 Random walk step length
The length of any of the steps between collisions is random. For any
collision process, the average number of collisions a particle has per
unit length corresponding to that process, which we'll label j, is njσj, where σj is the cross-section, and nj is the
density in the matter of the target species that has collisions of
type j. For example, if the particles are neutrons and the process
is uranium nuclear fission, nj would be the density of uranium
nuclei. The average total number of collisions of all types per unit
path length is therefore
where the sum is over all possible collision processes. Once again
Σt is an inverse
attenuation-length.
How far does a particle go before having a collision? Well, even for
particles with identical position and velocity, it varies
statistically in an unpredictable way. However, the probability of
having a collision in the small distance l→ l+dl, given that the
particle started at l (in other words, earlier collisions are
excluded), is Σt dl. This incremental collision probability
Σtdl is independent of prior events.
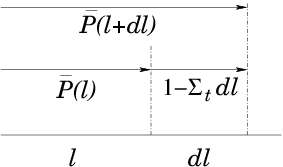
Figure 12.2: The probability,
, of survival without a
collision to position l decreases by a multiplicative factor
1−Σ
tdl in an increment dl.
, then the probability that it survives at
least as far as l+dl is the product of
times the
probability 1−Σtdl that it does not have a collision in
dl:
|
|
-
P
|
(l+dl) = |
-
P
|
(l)(1−Σtdl) |
| (12.2) |
Hence
The solution of this differential equation is
|
|
-
P
|
(l) = exp(− | ⌠
⌡
|
l
0
|
Σt dl), |
| (12.4) |
where l is measured from the starting position, so
. Another equivalent way to define
is: the
probability that the first collision is not in the interval
0→l. The complement
is therefore the
probability that the first collision is in 0→l. In other
words,
is a cumulative probability. It is the
integral of the probability distribution p(l)dl that the (first)
collision takes place in dl at l; so:
|
p(l) = |
dP
dl
|
= − |
dl
|
= Σt |
-
P
|
= Σt exp(− | ⌠
⌡
|
l
0
|
Σt dl) . |
| (12.5) |
To decide statistically where the first
collision takes place for any specific
particle, therefore, we simply draw a random number (uniform variate)
and select l from the cumulative distribution P(l) as
explained in section 11.2 and illustrated in Fig. 11.1. If we are dealing with a step in which Σt can
be taken as uniform, then P(l) = 1−exp(−Σt l), and the
cumulative function can be inverted analytically as
l(P)=−ln(1−P)/Σt.
12.1.2 Collision type and parameters
Having decided where the next collision happens, we need to decide
what sort of collision it is. The local rate at
which each type j of collision is occuring is njσj and the
sum of all njσj is Σt. Therefore the fraction of
collisions that is of type j is njσj/Σt.
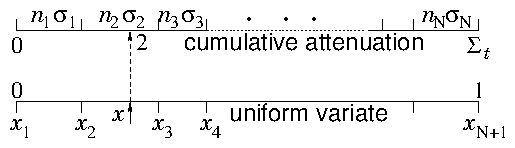
Figure 12.3: Deciding the collision type based upon a random number x.
then a single random draw x determines j by the condition xj ≤ x < xj+1. This is just the process of drawing from a discrete
probability distribution. Our previous examples were the Poisson
distribution, and the weighting of discrete particles for flux injection.
Once having decided upon the collision process j, there are
(usually) other parameters of the collision to be decided. For
example, if the collision is a scattering event, what is the
scattering angle and the corresponding new scattered velocity
v which serves78 to determine the starting condition of the next
step? These random parameters are also determined by statistical
choice from the appropriate probability distributions, for example the
normalized differential cross-section per unit scattering angle.
12.1.3 Iteration and New Particles
Once the collision parameters have been decided, unless the event was an
absorption, the particle is restarted from the position of collision
with the new velocity and the next step is calculated. If the particle
is absorbed, or escapes from the modelled region,
then instead we start a completely new particle. Where and how it is
started depends upon the sort of radiation transport problem we are
solving. If it is transport from a localized known source, then that
determines the initialization position, and its direction is
appropriately chosen. If the matter is emitting, new particles can be
generated spread throughout the volume. Spontaneous
emission, arising independent of the level
of radiation in the medium, is simply a
distributed source. It serves to determine the distribution of brand
new particles, which are launched once all active particles have been
followed till absorbed or escaped. Examples of spontaneous emission
include radiation from excited atoms, spontaneous radioactive decays
giving gammas, or spontaneous fissions giving neutrons. However,
often the new particles are "stimulated"
by collisions from the transporting particles. Fig. 12.4
illustrates this process. The classic nuclear example is induced
fission producing additional neutrons. Stimulated emission arises as a
product of a certain type of collision.
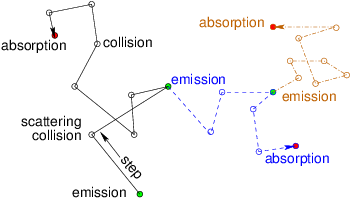
Figure 12.4: "Stimulated" emission is a source of new particles caused
by the collisions of the old ones. It can multiply the particles
through succeeding generations, as the new particles (different
line styles) give rise themselves to additional
emissions.
12.2 Tracking, Tallying and Statistical Uncertainty
The purpose of a Monte Carlo simulation is generally to determine some
averaged bulk parameters of the radiation particles or the matter
itself. The sorts of parameters include, radiation flux as a function
of position, spectrum of particle energies, rate of occurrence of
certain types of collision, or resulting state of the matter through
which the radiation passes. To determine these sorts of quantities
requires keeping track of the passage of particles through the
relevant regions of space, and of the collisions that occur there.
The computational task of keeping track of events and contributions to
statistical quantities is often called "tallying".
What is generally done is to divide the region of interest into a
managable number of discrete volumes, in which the tallies of interest
are going to be accumulated. Each time an event occurs in one of these
volumes, it is added to the tally. Then, provided a reasonably large
number of such events has occurred, the average rate of the occurrence
of events of interest can be obtained. For example, if we wish to know
the fission power distribution in a nuclear reactor, we would tally
the number of fission collisions occurring in each volume. Fission
reactions release on average a known amount of total energy
E. So if the number occuring in a particular volume V, during a
time T is N, the fission power density is NE/VT.
The number of computational random walks that we can afford to track
is usually far less than the number of events that would actually
happen in the physical system being modelled. Each computational
particle can be considered to represent a large number of actual
particles all doing the same thing. The much smaller computational
number leads to important statistical fluctuations, uncertainty, or
noise, that is a purely computational limitation.
The statistical uncertainty
of a Monte Carlo calculation is
generally determined by the observation that a sample of N random
choices from a distribution (population) of standard deviation S has
a sample mean μN whose standard deviation is equal to the
standard error S/√N. Each tally event acts like single random
choice. Therefore for N tally events the uncertainty in the quantity
to be determined is smaller than its intrinsic uncertainty or
statistical range by a factor 1/√N. Put differently, suppose the
average rate of a certain type of statistically determined event is
constant, giving on average N events in time T then the number n
of events in any particular time interval of length T is governed by
a Poisson probability, eq. (11.15) p(n) = exp(−N)Nn/n!. The standard deviation of this Poisson distribution
is √N. Therefore we obtain a precise estimate of the average rate of
events, N, by using the number actually observed in a particular
case, n, only if N (and therefore n) is a large number.
The first conclusion is that we must not choose our discrete tallying
volumes too small. The smaller they are, the fewer events will occur
in them, and, therefore, the less statistically accurate will be the
estimate of the event rate.
When tallying collisions, the first thought one
might have is simply to put a check mark against each type of
collision for each volume element, whenever that exact type of event
occurs in it. The difficulty with this approach is that it will give
very poor statistics, because there are going to be too few check
marks. To get, say, 1% statistical uncertainty, we would need 104
check marks for each discrete volume. If the events are spread over,
say 1003 volumes, we would need 1010 total collisions of
each relevant type. For, say, 100 collision types we are already up
to 1012 collisions. The cost is very great. But we can do better
than this naïve check-box approach.
One thing we can do with negligible extra effort is to add to the
tally for every type of collision, whenever any
collision happens. To make this work, we must add a variable amount to
the tally, not just 1 (not just a check mark). The amount we should
add to each collision-type tally, is just the fraction of all
collisions that is of that type, namely njσj/Σt. Of
course these fractional values should be evaluated with values of
nj corresponding to the local volume, and at the velocity of the
particle being considered (which affects σj). This process
will produce, on average, the same correct collision
tally value, but will do so with a total number of contributions bigger by
a factor equal to the number of collision types. That substantially improves the
statistics.
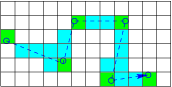
Figure 12.5: Tallying is done in discrete volumes. One can tally every
collision(green) but if the steps are larger than the
volumes, it gives better statistics to tally every volume the
particle passes through(blue).
and the scalar flux
density79 to
. If collisional lengths (the length of the random walk step) are
substantially larger than the size of the discrete volumes, then there
are more contributions to the flux property tallies than there are
walk steps, i.e. modelled collisions. The statistical accuracy of the
flux density measurement is then better than the collision tallies
(even when all collision types are tallied for every collision) by a
factor approximately equal to the ratio of collision step length to
discrete volume side-length. Therefore it may be worth the effort to
keep a tally of the total contribution to collisions of type j that
we care about from every track that passes through every volume. In
other words, for each volume, to obtain the sum over all passages i:
. The extra cost of this process
is the geometric task of determining the length of a line during which
it is inside a particular volume. But if that task is necessary
anyway, because flux properties are desired, then it is no more work
to tally the collisional probabilities in this way.
Importance weighting
Another aspect of statistical accuracy
relates to the choice of initial distribution of particles, especially
in velocity space. In some transport problems, it might be that the
particles that penetrate a large distance away from their source are
predominantly the high energy particles, perhaps those quite far out
on the tail of a birth velocity distribution that has the bulk of its
particles at low energy. The most straightforward way to represent the
transport problem is to launch particles in proportion to their
physical birth distribution. Each computational particle then
represents the same number of physical particles. But this choice
might mean there are very few of the high-energy particles that
determine the flux far from the source. If so, then the statistical
uncertainty of the far flux is going to be great.
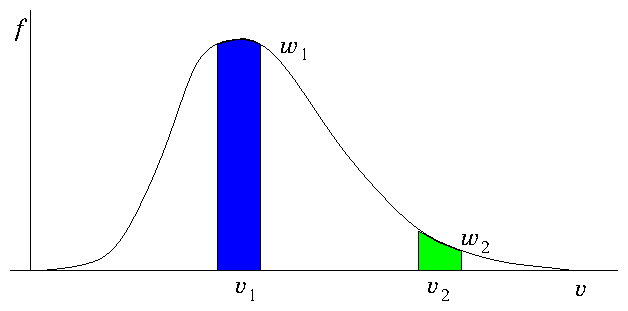
Figure 12.6: If all particles have the same weight, there are many more
representing bulk velocities (v
1) than tail velocities
(v
2). Improved statistical representation of the tail is
obtained by giving the tail velocities lower weight w
2. If the
weights are proportional to f then equal numbers of particles
are assigned to equal velocity ranges.
This process of weight multiplication between generations causes a
spreading of the weights. The ratio of the maximum to minimum
weight of each succeeding generation is multiplied by the birth
weight-ratio; so the weight range ratio grows geometrically. When
there is a very large range between the minimum and the maximum
weight, it becomes a waste of time to track particles whose weight is
negligibly small. So after the simulation has run for some time
duration, special procedures must be applied to limit the range of
weights by removing particles of irrelevantly small weight.
12.3 Worked Example: Density and Flux Tallies
In a Monte Carlo calculation of radiation transport from a
source emitting at a fixed rate R particles per second, tallies in
the surrounding region are kept for every transit of a cell by every
particle. The tally for density in a particular cell consists of
adding the time interval ∆ti during which a particle is in
it, every time the cell is crossed. The tally for flux density adds
up the time interval multiplied by speed: vi∆ti. After
launching and tracking to extinction a large number N of random
emitted particles, the sums are
|
Sn= |
∑
i
|
∆ti, Sϕ = |
∑
i
|
vi ∆ti. |
|
Deduce quantitative physical formulas for what the particle and flux
densities are (not just that they are proportional to these sums), and
the uncertainties in them, giving careful rationales.
A total of N particles tracked from the source (not
including the other particles arising from collisions that we also had
to track), is the number of particles that would be emitted in a
time T=N/R. Suppose the typical physical duration of a particle
"flight" (the time from launch to absorption/loss of the particle
and all of its descendants) is τ.
If T >> τ, then it is clear that the calculation is equivalent to
treating a physical duration T. In that case almost all particle
flights are completed within the same physical duration T. Only
those that start within τ of the end of T would be physically
uncompleted; and only those that started a time less than τ
before the start of T would be still in flight when T starts. The
fraction affected is ∼ τ/T, which is small. But in fact, even
if T is not much longer than τ, the calculation is still equivalent to
simulating a duration T. In an actual duration T there would then
be many flights that are unfinished at the end of T, and others that are
part way through at its start. But on average the different types of
partial flights add up to represent a number of total flights equal to
N. The fact that in the physical case the partial flights are of
different particles, whereas in the Monte Carlo calculation they are
of the same particle, does not affect the average tally.
Given, then, that the calculation is effectively simulating a duration
T, the physical formulas for particle and flux
densities in a cell of volume V are
|
n = Sn/TV = SnR/NV, and ϕ = Sϕ/TV=Sϕ R/NV. |
|
To obtain the uncertainty, we require additional sample sums. The
total number of tallies in the cell of interest we'll call
. We may also need the sum of the squared tally contributions
and
. Then finding Sn and Sϕ can be considered to be a
process of making S1 random selections of typical transits of the
cell from probability distributions whose mean contribution per
transit are Sn/S1 and Sϕ/S1 respectively. Of course the
probability distributions aren't actually known, they are indirectly
represented by the Monte Carlo calculation. But we don't need to know
what the distributions are, because we can invoke the fact that the
variance of the mean of a large number (S1) of samples from a
population of variance σ2 is just σ2/S1. We
need an estimate of the population variance for density and flux density. That
estimate is provided by the standard expressions for variance:
|
σn2= |
1
S1−1
|
[Sn2−(Sn/S1)2], σϕ2= |
1
S1−1
|
[Sϕ2−(Sϕ/S1)2]. |
|
So the uncertainties in the tally sums when a fixed number S1 ≈ S1−1 of
tallies occurs are
However, there is also uncertainty arising from the fact that the
number of tallies S1 is not exactly fixed, it varies from
case to case in different Monte Carlo trials, each of N
flights. Generally S1 is Poisson distributed, so its variance is
equal to its mean σS12=S1. Variation δS1 in
S1 gives rise to a variation approximately (Sn/S1) δS1
in Sn. Also it is reasonable to suppose that the variances of
contribution size, σn2 and σϕ2 are not correlated
with the variance arising from number of samples
(Sn/S1)2σS12, so we can simply add them and arrive at
total uncertainty in Sn and Sϕ, (which we write δSn
and δSϕ)
Usually, σn <~Sn and σϕ <~Sϕ, in which
case we can (within a factor of √2) ignore the σn and
σϕ contributions, and approximate the fractional
uncertainty in both density and flux as
. In this
approximation, the squared sums Sn2 and Sϕ2 are unneeded.
Exercise 12. Monte Carlo Statistics
1. Suppose in a Monte Carlo transport problem there are Nj different
types of collision each of which is equally likely. Approximately what
is the statistical uncertainty in the estimate of the rate of
collisions of a specific type i when a total Nt >> Nj of collisions
has occurred
(a) if for each collision just one contribution to a specific
collision type is tallied,
(b) if for each collision a proportionate (1/N) contribution to every collision
type tally is made?
If adding a tally contribution for any individual collision type has a
computational cost that is a multiple f times the rest of the cost of
the simulation,
(c) how large can f be before it becomes
counter-productive to add proportions to all collision type tallies
for each collision?
2. Consider a model transport problem represented by two particle
ranges, low and high energy: 1,2. Suppose on average there are
n1 and n2 particles in each range and n1+n2=n is fixed. The
particles in these ranges react with the material background at
overall average rates r1 and r2.
(a) A Monte Carlo determination of the reaction rate is based on a
random draw for each particle determining whether or not it has
reacted during a time T (chosen such that r1T,r2T << 1). Estimate the fractional statistical uncertainty in the reaction
rate determination after drawing n1 and n2 times respectively.
(b) Now consider a determination using the same r1,2, T, and
total number of particles, n, but distributed differently so that
the numbers of particles (and hence number of random draws) in the two
ranges are artificially adjusted to n1′, n2′ (keeping
n1′+n2′=n), and the reaction rate contributions are appropriately
scaled by n1/n1′ and n2/n2′. What is now the fractional
statistical uncertainty in reaction rate determination? What is the
optimum value of n1′ (and n2′) to minimize the uncertainty?
3. Build a program to sample randomly from an exponential
probability distribution p(x)=exp(−x), using a built-in or library
uniform random deviate routine. Code the ability to form a series of
M independent samples labelled j, each sample consisting of N
independent random values xi from the distribution p(x). The samples
are to be assigned to K bins depending on the sample mean
. Bin k contains all samples for which
xk−1 ≤ μj < xk, where xk=k∆. Together they form a
distribution nk, for k=1,...,K that is the number of samples with μj
in the bin k. Find the mean
and variance
| σn2= |
K
∑
k=1
|
nk [(k−1/2)∆−μn]2/(M−1)
|
of this distribution nk, and compare them with the
prediction of the Central Limit Theorem, for N=100, K=30,
∆ = 0.2, and two cases: M=100 and M=1000. Submit the
following as your solution:
- Your code in a computer format that is capable of being
executed.
- Plots of nk versus xk, for the two cases.
- Your numerical comparison of the mean and variance, and comments
as to whether it is consistent with theoretical expectations.