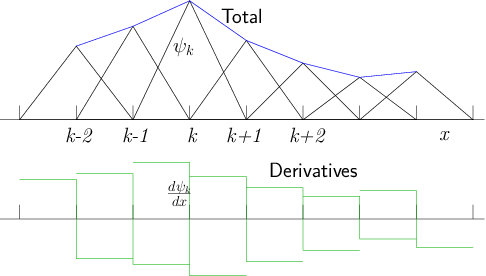
Figure 13.1: Localized triangle functions in one dimension, multiplied by
coefficients, sum to a
piecewise linear total function. Their derivatives are box functions
with positive and negative parts. They overlap only with adjacent functions.
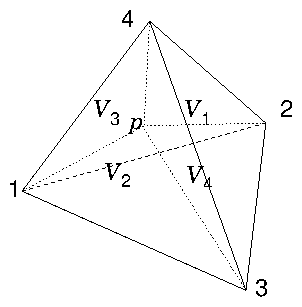
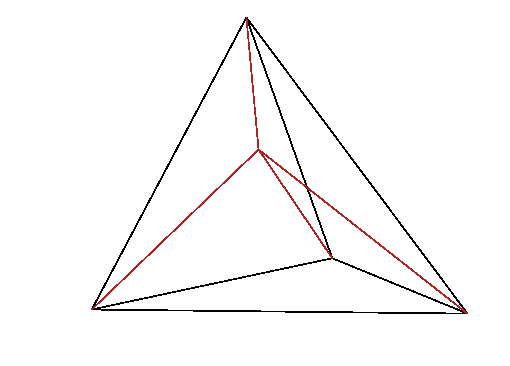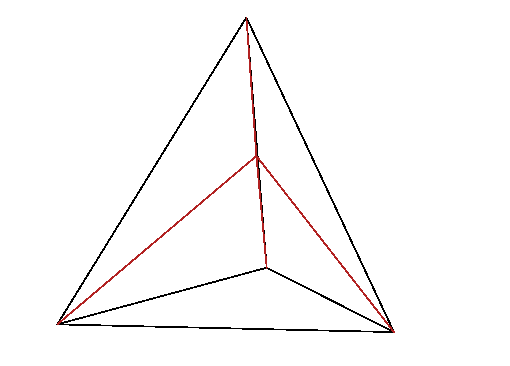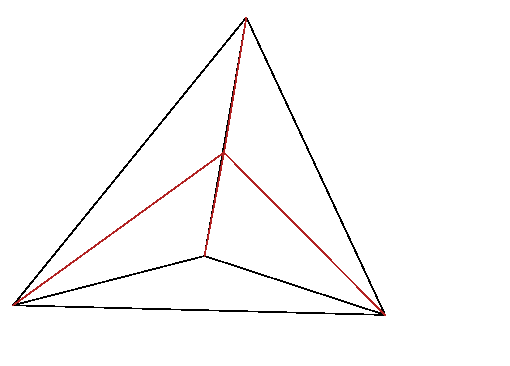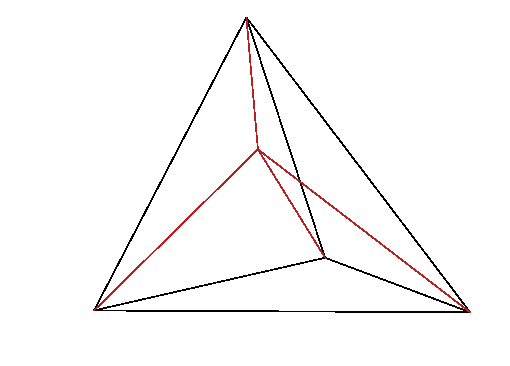
Figure 13.2: In linear interpolation within a tetrahedron, the lines from
a point p to the corner nodes of the tetrahedron, divide it into
four smaller tetrahedra, whose volumes sum to the total volume. The
interpolation weight of node k is proportional to the
corresponding volume, V
k.
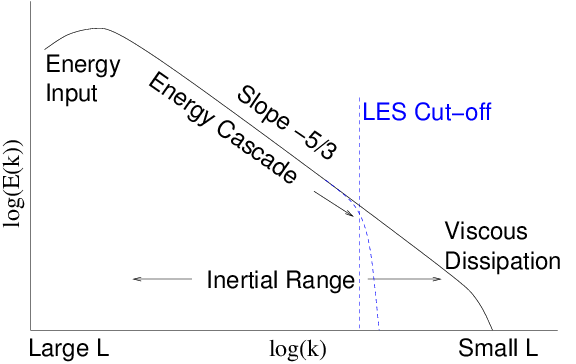
Figure 13.3: Schematic energy spectrum E(k) of turbulence as a function
of wave number k=2π/L. There is an inertial range where theory
(and experiments) indicate that a cascade of energy towards smaller
scales gives rise to a power law E(k) ∝ k
−5/3. Eventually
viscosity terminates the cascade. LES artificially cuts it off at
lower k.